
Predicting Credit Card Default
Predicting Credit Card Default
By Ross Glasmann
October 22, 2019
Introduction
Predicting when someone might miss a payment is is a valuable asset for many companies in the financial industry. Being able to detect when someone may default on their payments, on things such as loans as credit cards can help a financial institution make a better decision to who they give credit to. Predicting defaults is just one of many ways Machine Learning can help the banking industry. In this project, we will explore if it is possible to reliably predict if someone will default on their credit card payments. Since we are only predicting whether someone will default, or they won’t, this is a binary classification problem.
The Data
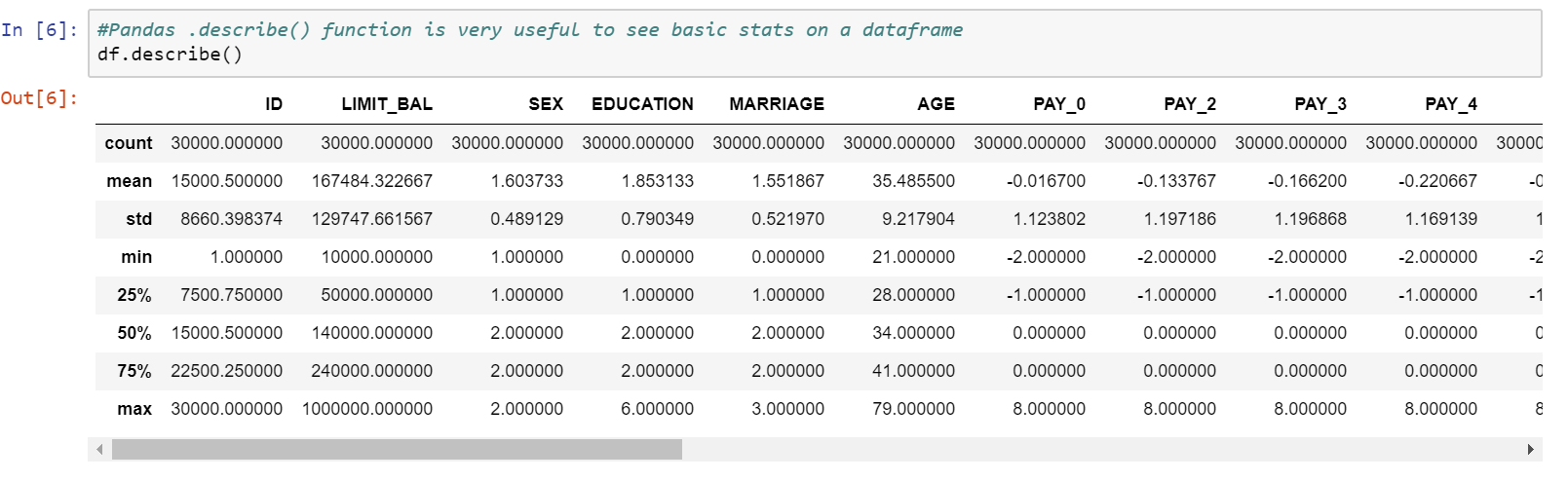
This dataset is originally from the UCI Machine Learning Repository. The data was collected in Taiwan, using six different data mining methods. The dataset consists of both categorical and numeric features and conveniently does not have any missing values. The features are also already ordinally encoded. This data requires minimal cleaning and changes to be ready for a model.
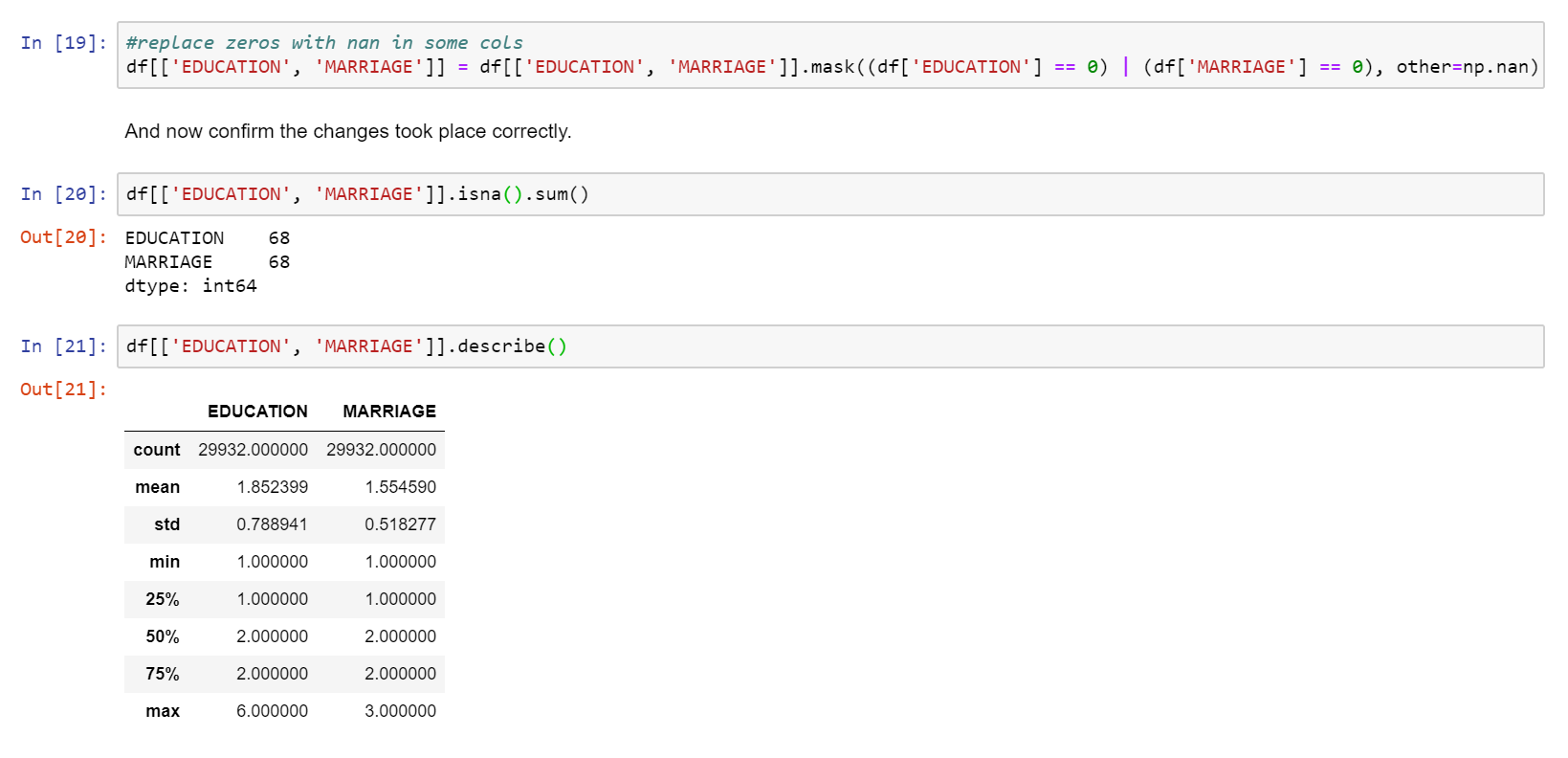
Some of the categorical variables had Zeros where there should have been missing values, so those were fixed.
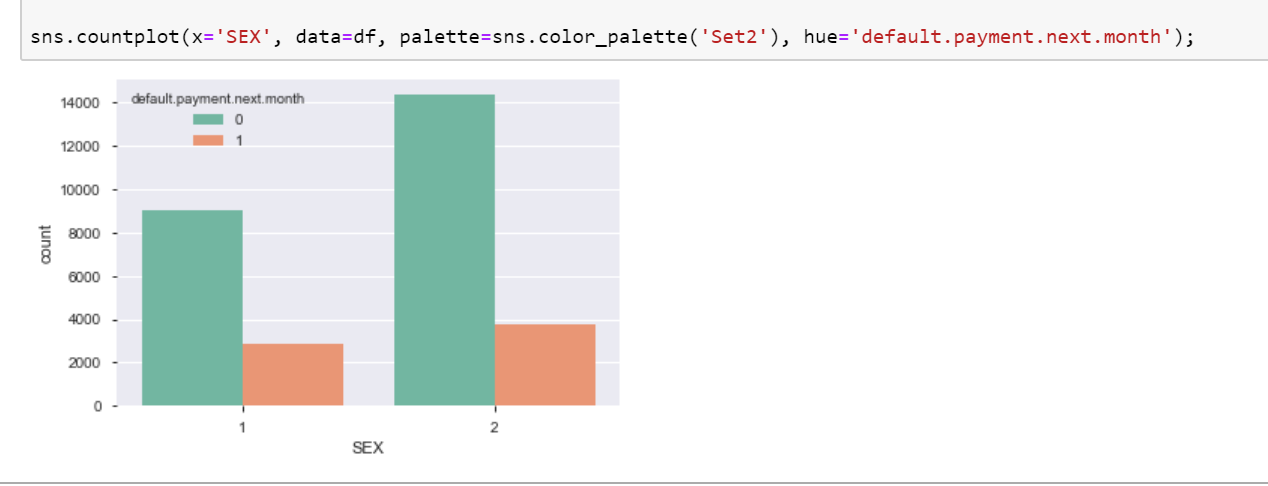 Some of the values in the EDUCATION column were also consolidated, because they all stood for the same thing, yet were labeled differently. That is the extent of data cleaning and feature engineering that was needed for this particular dataset. From this point, we are ready to prepare the model to make predictions.
Some of the values in the EDUCATION column were also consolidated, because they all stood for the same thing, yet were labeled differently. That is the extent of data cleaning and feature engineering that was needed for this particular dataset. From this point, we are ready to prepare the model to make predictions.

The Model
The first thing to do is to find the majority class baseline. This is the probability that you will choose either of the classes being predicted, by randomly guessing. For this dataset, the majority class baseline for NOT defaulting on payment is 77.88 percent, and 22.12 percent for defaulting.

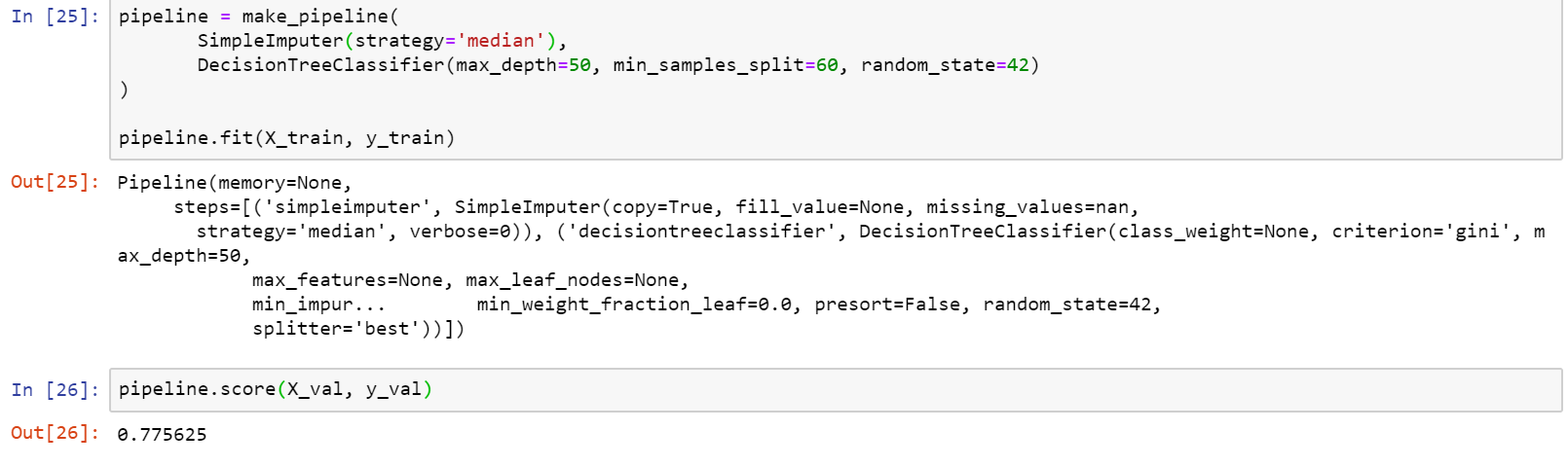
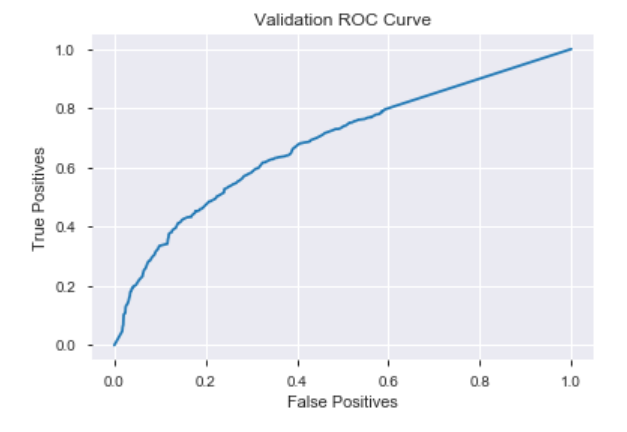
The first model I chose was the Random Forest Classifier, which is a decision tree based model. After splitting the data with a train, validate, test split, the first model was put into a sklearn pipeline, and trained with the training set of data. The result of this model was not impressive, and in fact, performed worse than the baseline with an accuracy score of 77.43 percent. Since the class we are prediction is unbalanced, accuracy may not be the best way to score the model. Instead, we will also test how well the model performs using the AUC (Area Under the Curve) ROC (Receiver Operating Characteristics ) curve. This is a performance measurement tool for classification problems. It compares the number of true positive results, to the number of false positives. The higher the AUC, the better the model is performing. The ROC AUC baseline is a score of 0.5. The first model got a score of 0.6183 from the validation set of data.
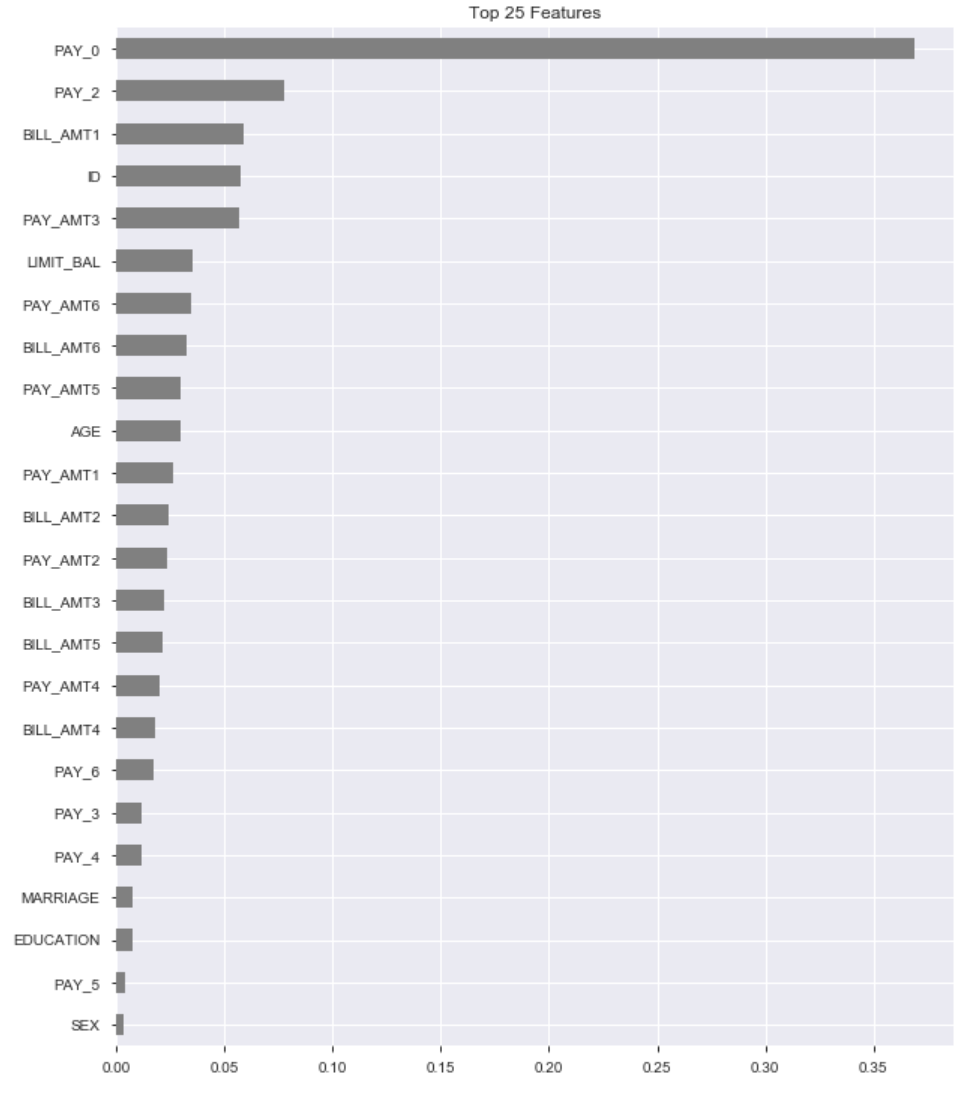
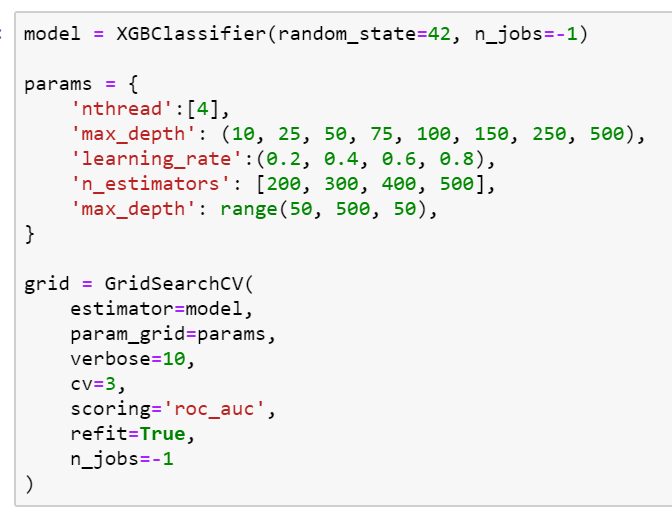
The next model tried is an xgboost model called XGBoostClassifier. This is another decision tree based model, but it is usually able to improve accuracy over a normal decision tree or random forest. With these models, hyperparameters need to be tuned to get the best performance. A hyperparameter is a setting for the model, that can be changed, and changes the way the model performs. For this, I used sklearns GridSearchCV. After finding the best parameters, the final model was ready to be trained.
The final model got an accuracy score of 80.75 percent, which is an improvement over the first model and the majority class baseline. The ROC AUC score was very similar to that of the first model, scoring 0.6445 with the test data.
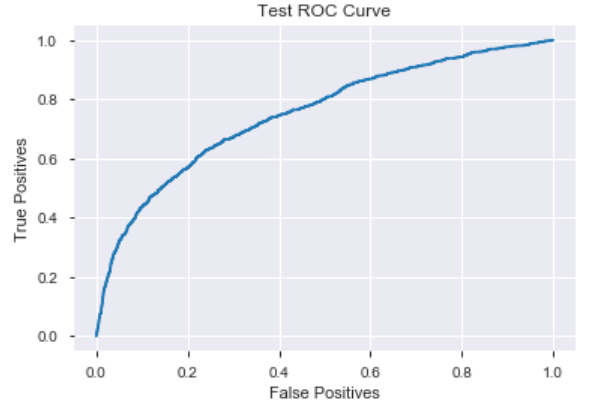
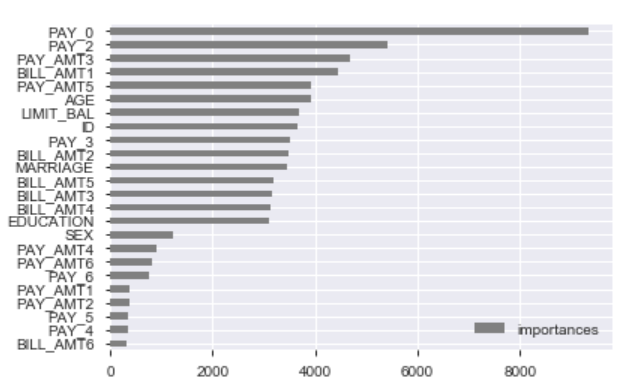
Conclusion
To conclude, this model is not something that should be used in a real-world situation, but the model was able to beat its majority class baseline. Maybe with more data or a different Machine Learning algorithm, these scores can be made higher. When it comes to classification models such as this one, scoring with AUC ROC is a better way of measuring the model’s performance than just accuracy. I am overall happy with how well this model did.